BIG DATA, THE CYCLICAL UNIVERSE AND THE END OF SCIENCE
| March 5, 2014
I was reading a piece in Artforum by Mario Carpo on big data and how it is being used by a new wave of architects. He made some surprising comments—none of which relate to architecture—that sort of blew my mind.
He pointed out that for many hundreds of years, science has been about discovering the essences behind phenomena—it is a method to find the simple laws and rules that govern our universe. Science presumes that there are such guiding principals to be found. Science has faith that these principals exist. We who subscribe to this faith believe all is not random and chaotic.
This last part, science and religion have in common. They both believe that ordering principles exist. Of course in religion, the principle behind all the other principles is divine—supernatural. It is beyond man and nature; outside of our world. With science there is a similar faith, but that faith says that the laws and principles are what makes up our world—they are us and we are them. In a sense, the rules are God.
Carpo points out that as the ability to crunch huge amounts of data advances, the need to know what makes things tick, what laws underlie and govern our world, diminishes. If weather, for example, is being analyzed, and all the events and their magnitude and duration duly archived in massive data banks, then you don’t need to know why there are storms or floods or melting ice caps; you don’t need to know that they might be caused by gasses in the atmosphere that were largely put there by people and what those gases and particles do to light and how they work on a molecular level. You don’t need to know the why at all—you only need the data, and then statistically one can say, for example, that a flood will happen in a specific location every so many years, because that’s what has happened in the past.
Data is predictive, but in a very simple way. It might never presume something new and unexpected will happen (though it will allow for the occasional black swans, but that’s statistical too)—it won’t get distracted by the universe with all its beauty and strangeness. It will dispassionately look at what has happened before and coolly say, based on those events, what will happen next.
In many areas this is pretty reliable. Of course, one has to give some suggestions to the machines as to what sorts of patterns to look for: big storms in weather forecasting or seasonal urges for pumpkin pies, for example. In other areas it is pretty useless. Dating websites and services run on algorithms—the more data they collect the more they might predict a successful outcome, based on past experience.
It turns out that dating and matchmaking algorithms don’t really work. Tom Whipple quotes a professor who studied them in an article he wrote in Intelligent Life magazine:
“These claims,” Professor Eli Finkel from Northwestern University wrote, ”are not supported by credible evidence.” In fact, he said, there is not "a shred of evidence that would convince anybody with any scientific training". The problem is, we have spent a century studying what makes people compatible—by looking at people who are already together, so we know they are compatible. Even looking at guaranteed, bona-fide lovebirds has produced only weak hypotheses—so using these data to make predictions about which people could fall in love with each other is contentious.
Despite the failure of these services, they are hugely popular. People want them to work. Our faith runs counter to the facts.
The faith part of science—the belief that there are underlying laws and explanations—will possibly be abandoned if we adopt big data as a guide to the universe. One doesn’t need to know why the apple falls from a tree at a specific rate (the law of gravity). One only needs to see that that is what always happens, accept that fact, and log in that in such and such a situation, that is what will happen—the apple will fall. That there is a law that can be applied to predict that and to even predict how apples will fall on Mars is irrelevant—when you have infinite data you don’t need to know the why of anything.
Then you get into a situation like the Jorge Luis Borges story about the ultimate map that describes a place perfectly in every detail— a map which, of course, ends up being as big as the area it describes. We’re heading to a point where the amount of data will eventually equal the amount of stuff in the world; a one to one correspondence. Everything is being watched, mapped and analyzed—the data is hoarded, but only analyzed in a funky kind of way. Parallel processing of data sometimes produces some surprising connections when seemingly unrelated clumps of data are mashed together: the people who buy new phones immediately might be revealed, when their data are cross-referenced, to be the very same people who wear synthetic knits. A marketing opportunity is born! But what is the underlying cause of that connection? Is there even a reason? Who cares! We can now more efficiently market certain clothes to phone buyers. No one needs to know why anything happens ever again.
Based on the behavior of insurgents that have been tracked, the NSA may feel that any occurrence of a similar pattern of behavior warrants watching: eating Pringles and playing in a video arcade, for example. If your behavior matches this too closely you could be arrested, though you’ve done nothing. As before, this reliance on data doesn’t ask why the insurgency, what caused it, or what those people want—it doesn’t look for underlying causes, it simply and dispassionately (or so we are led to think) goes about its business of crunching numbers.
From Corey Doctorow (via Boing Boing):
The Chicago Police Department has ramped up the use of its "predictive analysis" system to identify people it believes are likely to commit crimes. These people, who are placed on a "heat list," are visited by police officers who tell them that they are considered pre-criminals by CPD, and are warned that if they do commit any crimes, they are likely to be caught.
The CPD defends the practice, and its technical champion, Miles Wernick from the Illinois Institute of Technology, characterizes it as a neutral, data-driven system.
Philip K. Dick was right again! The world of Minority Report is here.
The thing is, the human factor hasn’t gone away. It’s humans who tell the machines what patterns to look for, which other patterns to compare them to and how to organize all those numbers.
Here is a visual analysis of edits on Wikipedia categories:
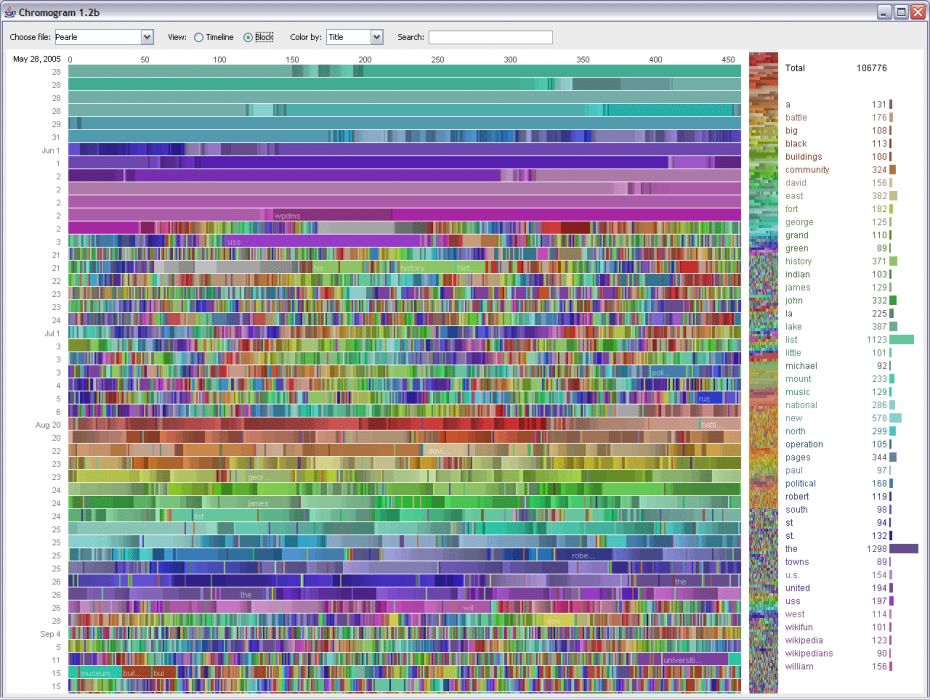
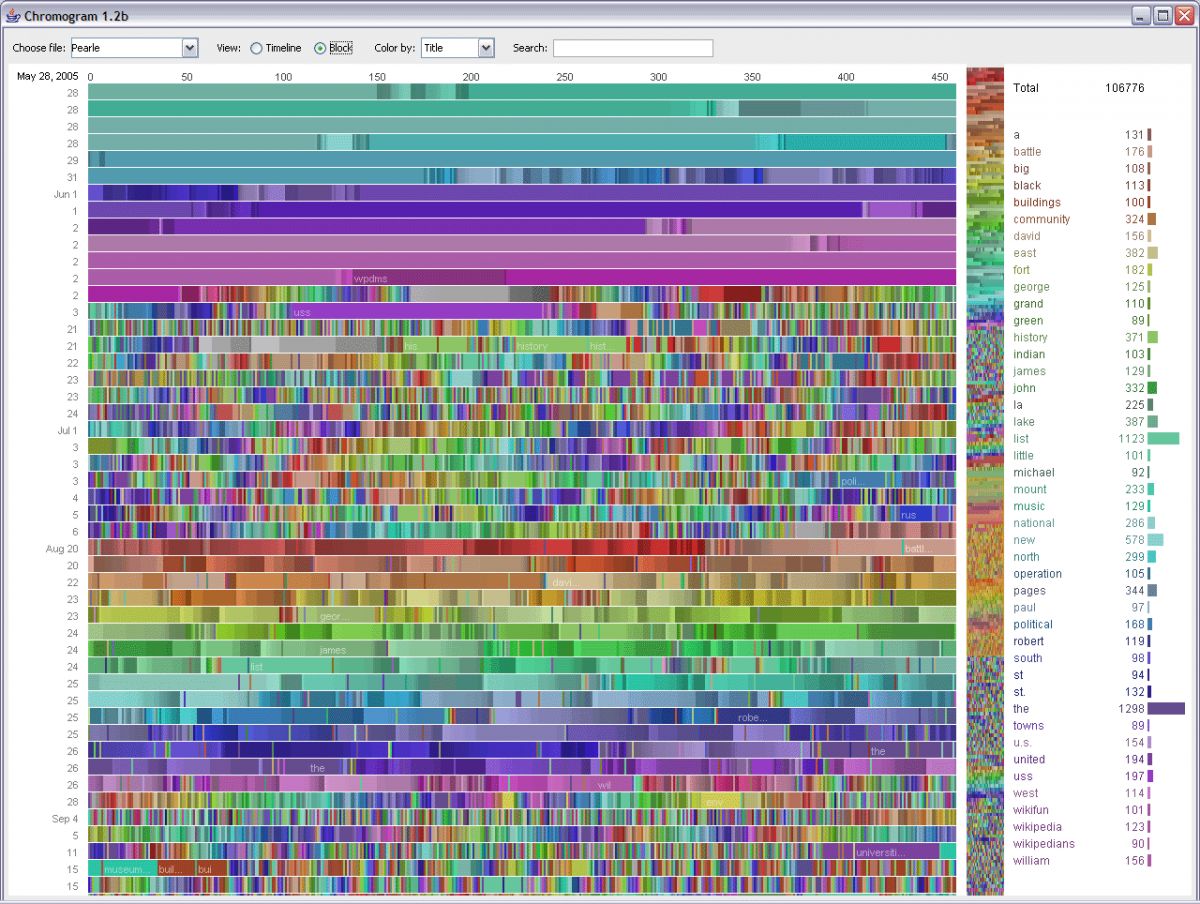 Source">
Source">
What is apparent to me is that all the categories were chosen by humans. The patterns may exist, many patterns may exist, but it is humans (and probably only a few of them) who have named them and chosen which ones are significant. So, like all programs, software and algorithms, there is a human hand meddling somewhere.
The foibles and prejudices of us humans finds a way into the most objective seeming algorithms and how the data is analyzed. Objectivity is a myth. So far. Until the machines are capable of finding emergent patterns on their own (which might not be too far off, I suspect), the intervention of fallible, ideologically and financially motivated humans will continue to guide the analytics.
One might almost welcome the machines taking over in this case. There’s a now-famous case of the young girl who was marketed diapers and her dad complained to the online company who was trying to sell her these things. “My daughter is not pregnant” he insisted. It soon was revealed that dad was wrong—but the algorithm and the data knew.
Science believes in a world where time is linear, though the laws of the universe predict that certain things will recur. Apples will fall from trees. But science doesn’t believe that the same apple will fall from the same tree more than once. One wonders if when the machines take over, will we truly see an end to science and the birth of a world that is—as the Hindu’s, Maya and many other have described it—an endless eternal loop of history playing itself out and then repeating over and over forever? Everything that happens simply a repetition of something that has happened before.
DB



